log
assets
第二节讲义_1682136737988_0
journals
loom
pages
static
css
fonts
inter
icons
img
js
excalidraw-assets
locales
pdfjs
cmaps
tags
对比学习
- 对比图
- $red代理任务
- 自监督学习大致可以分为两类
- Generative methods(生成方法)
- 自编码器
- 对比:对像素级细节进行重构
- 对数据样本编码成特征在解码重构
- 重构的效果好则说明模型学到了比较好的特征表达
- 对比式方法
- 对比:只需要在特征空间上学习刀片区分性(核心通过计算样本特征的距离,拉进正样本,拉远负样本)。不会过分关注语义细节,而更关注更抽象的语义信息
- 将数据分别与正样本和负样本在特征空间对比
- 难点在于如何构造正负样本
- 自编码器
- contrastive methods(对比方法)
- Generative methods(生成方法)
- 1.百花齐放
- instdisc

- 核心理论:分类的原因不是因为有标签,而是这些图像长得太像了
- 提出了$red个体判别的任务(每个图片都是自己的类)+NCE Loss+如何存放负样本
- 通过一个卷积神经网络,把所有的图片都编码成一个特征,希望所有的特征在特征空间内可以尽可能的分开
- 如何训练神经网络?
- 对比学习
- 正样本:
- 图片本身+数据增强
- 负样本:
- 数据集中其他图片
- 负样本所有特征存在memory bank
- 本文选取了128维度
- nceloss计算损失,更新网络,更新特征
- 小技巧:
- proximal regularization
- 给模型的训练加了一个约束,是的memory bank中的特征进行动量式更新
- proximal regularization
- {:height 174, :width 689}

- 有篇文章
- 将一个人观看的不同的视角当做一个对比学习
- instdisc
- 2.cv双雄
- mocov1
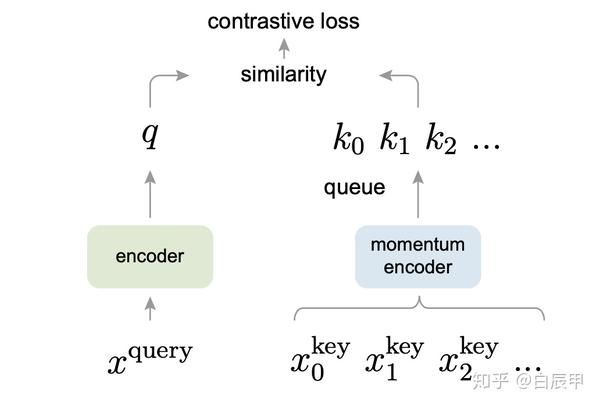 {:height 494, :width 719}
{:height 494, :width 719}- MoCo 的主要贡献就是把之前对比学习的一些方法都归纳总结成了一个字典查询的问题,它提出了两个东西
- 队列
- 动量编码器
从而去形成一个又大又一致的字典,能帮助更好的对比学习
- MoCo跟Inst Disc是非常相似的
- 它用队列取代了原来的memory bank作为一个额外的数据结构去存储负样本
它用动量编码器去取代了原来loss里的约束项,从而能达到动量的更新编码器的目的,而不是动量的去更新特征,从而能得到更好的结果
但是整体的出发点以及一些实现的细节都是非常类似的 - MoCo 的这个实现细节:
- 首先从模型的角度上来说,它用的是残差网络,它的基线模型都用的是Res 50,其实Inst Disc也用的是Res 50,模型上是一样的
最后每个图片的特征维度也沿用了128维
它也对所有的特征做了L2 归一化
至于目标函数,MoCo 采用的是info NCE,而不是像Inst Disc是NCE但是算loss用的温度也是0.07
数据增强的方式也是直接借鉴过来的
包括后面训练的学习率0.03,训练200个epochs这些也都是跟Inst Disc保持一致的
所以,说MoCo是Inst Disc一个改进型工作也不为过,但是MoCo真正出色的地方其实有两点 - 一个是它的改进真的是简单有效,而且有很大的影响力的,比如说它的动量编码器,在后面的SimCLR、BYOL,一直到最新的对比学习的工作都还在使用。它提出的这个技术不仅在当时帮助 MoCo第一次证明了无监督学习也能比有监督特征学习的预训练模型好,而且还能产生持续的影响力,帮助之后的工作取得更好的结果,所以它的改进很深刻而且很有效
另外一个可圈可点的地方就是MoCo的写作真的是高人一等非常不一样,其实如果是一个简单直白的写作方式,在语言里先介绍对比学习是什么,然后再介绍之前的工作有哪些,比如说有端到端的工作,然后有看Inst Disc,这个 memory bank 的这个工作,然后它们各自都有各自的缺点和局限性,所以说提出MoCo ,用队列去解决大字典的问题,用动量编码器去解决字典特征不一致的问题,最后结果很好,第一次证明了在下游任务中用一个无监督训预训练的模型也会比有监督预训练的模型好,那这种写法也是一种很简洁直白明了的写作方式,大部分论文的写作都是按照这个套路来的。但是MoCo的作者明显就高了一个层次:引言上来先说这个cv和nlp之间的区别,以及到底为什么无监督学习在 cv 这边做的不好,然后第二段它才开始讲对比学习,但是它也不是细细地去讲对比学习,或者细细的去讲那些方法,而是直接把之前所有的方法都总结成了一个字典查找的问题,所以直接把问题给归纳升华了,然后在这个框架下,就是 cv 和 nlp 大一统的框架以及所有的对比学习也都大一统的框架之下,然后作者提出了 MoCo 这个框架,希望能用一个又大又一致的字典去整体地提高对比学习的性能,那论文的scope整体就扩大了,远不是之前的那种简单的写作方式可以比的,而且这样的写作风格呢还延续到了方法部分,在3.1里,作者没有先写一个模型总览图,也没有具体说是什么模型、什么任务,而是先从最后的目标函数入手,说是用info NCE来做的,先把正负样本定义了一下,然后再去讲网络结构然后再去讲实现细节和伪代码,而且在3.1里,为了让MoCo看起来更普适,在这里没有直接定义输入是什么,也没有定义这个网络结构到底是什么样的,它是说什么样的输入都可以,比如说它可以是图片,也可以是图片块,或者是上下文的图片块(文献46其实就是cpc),至于网络,它说query 的编码器和key的编码器既可以是相同的(invariant spread),也可以是部分共享的,还可以是完全不同的(文献56就是cmc,因为是多个视角嘛所以是多个编码器)
- simple clr

- mlp layer
- augmentation
- cos
- epochs
- moco v2(可以做很多)
- 能玩的动,可以参考思路

- simple clr v2
- 大模型(骨干网络更强)
- mlp层 2层就够了 (两层lu)
- moco的动量编码器
- 提升了一个点
- $redswav(给定一个图片,不同视角特征可以预测其他视角特征) #重点论文
- mocov1
- 3.不用负样本,也可以做深度学习
- 4.transformer
- moco v3 用了transformer时代

- 骨干网络从残差换成了vit
- $red出现了随着batch norm增大,会出现结果下降
- 解决:冻结patch projection
- 论文

- 其中centering 是算均值

- moco v3 用了transformer时代






{kind=link}
{kind=link}
_-_image_1705670873910_0.png){kind=link}
_-_image_1705670919100_0.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table Of Contents